

Twitter で評判の良い browser-use を試してみたいと思います。
なお、なかなか良かったので、そのまま Langchainとの連携させました。
公式 Github
https://github.com/browser-use/browser-use
Pythonは 3.11 が必要です。
インストール
$ pip install browser-use
$ playwright install起動テスト
ほぼドキュメント��のままですが、LLMを gpt-4o-mini に変更し、api_key を brouse-use 専用のものに差し替えました。
import os
from langchain_openai import ChatOpenAI
from browser_use import Agent
import asyncio
api_key = os.getenv("OPENAI_API_KEY_BROUSERUSE")
async def main():
agent = Agent(
task="Find a one-way flight from Bali to Oman on 12 January 2025 on Google Flights. Return me the cheapest option.",
llm=ChatOpenAI(model="gpt-4o-mini", openai_api_key=api_key),
)
result = await agent.run()
print(result)
asyncio.run(main())
ブラウザが立ち上がり、操作可能な要素をハイライトしてナンバリングしています。
ログを見ると、要素を index で管理してクリックしたりしています。
INFO [agent] ? Memory: The task is to find a one-way flight from Bali to Oman on 12 January 2025 on Google Flights.
INFO [agent] ? Next goal: Open Google Flights and enter the flight search parameters.
INFO [agent] ?? Action 1/5: {“open_tab”:{“url”:”https://www.google.com/flights”}}
INFO [agent] ?? Action 2/5: {“input_text”:{“index”:1,”text”:”Bali”}}
INFO [agent] ?? Action 3/5: {“input_text”:{“index”:2,”text”:”Oman”}}
INFO [agent] ?? Action 4/5: {“input_text”:{“index”:3,”text”:”2025-01-12″}}
INFO [agent] ?? Action 5/5: {“click_element”:{“index”:4}}
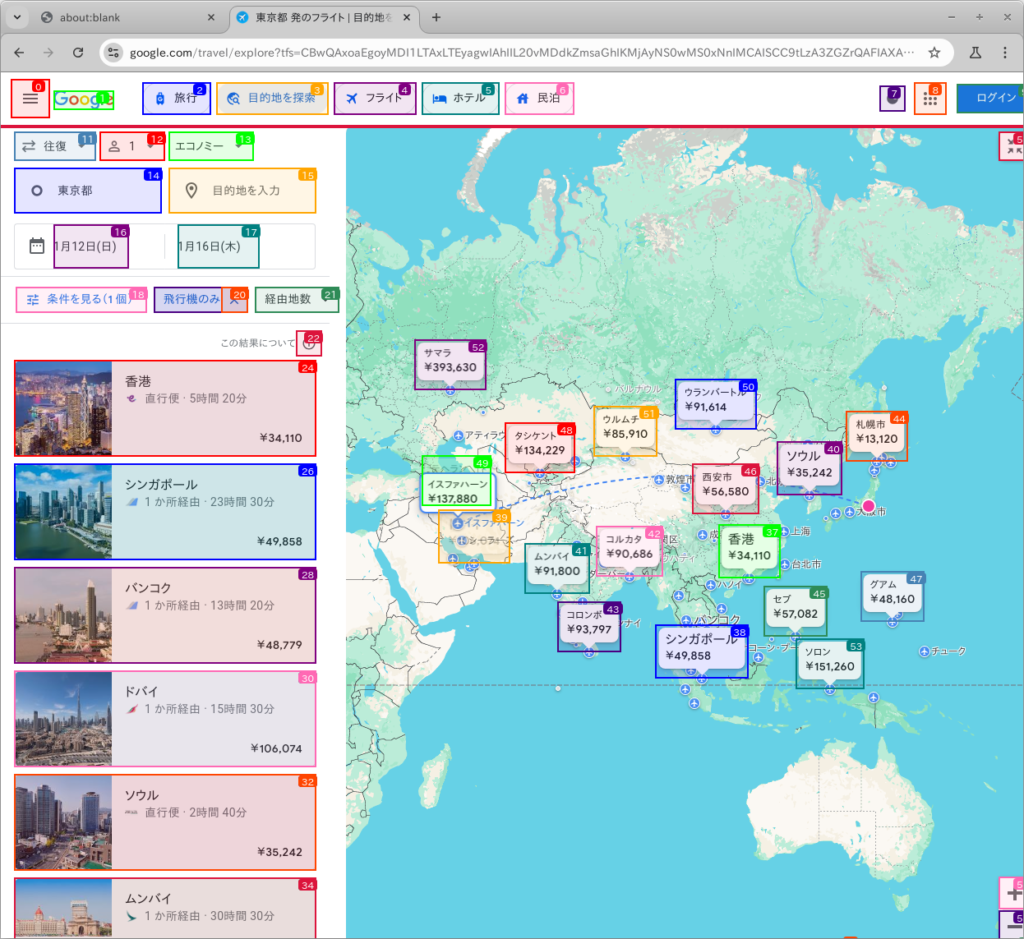
そして最終的な回答は
the cheapest one-way flight option found is to Hong Kong, with a direct flight taking 5 hours 20 minutes for \34,110.でした。
何をしているのかがよくわかって素敵です。
なお、ヘッドレスモードでも動きます。
LangChain との連携
これ単体でも素晴らしいですし、作者は DB 連携なども作るつもりのようですが、そのへんはやはり Langchain本体からやりたいです。
レスポンスの改変
https://github.com/browser-use/browser-use/blob/main/examples/custom_output.py
Examples の中に custom_output.py があるのでそれを参考しながら、Langchain RunnablePassthrough に対応させます。
ToolBrouserUse.py
import os
import asyncio
from typing import Any, Dict, Optional, ClassVar
from pydantic import BaseModel
from langchain.schema.runnable import RunnablePassthrough
from langchain_openai import ChatOpenAI
from browser_use import ActionResult, Agent, Controller
from browser_use.browser.browser import Browser, BrowserConfig
class Article(BaseModel):
title: str
url: str
description: str
class DoneResult(BaseModel):
articles: list[Article]
class BrowserUseOutput(BaseModel):
result: str
status: str = "success"
error: Optional[str] = None
class ToolBrouserUse(RunnablePassthrough):
DEFAULT_HEADERS: ClassVar[dict] = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
def __init__(self,):
super().__init__()
async def _process_browser_task(self, task: str) -> str:
browser = Browser(
config=BrowserConfig(
headless=True,
)
)
api_key = os.getenv("OPENAI_API_KEY_BROUSERUSE")
controller = Controller()
# Register the Done action
@controller.registry.action("Done with task", param_model=DoneResult)
async def done(params: DoneResult):
return ActionResult(is_done=True, extracted_content=params.model_dump_json())
llm = ChatOpenAI(model="gpt-4o-mini", openai_api_key=api_key)
try:
agent = Agent(
task=task, llm=llm, controller=controller, browser=browser
)
history = await agent.run()
result = history.final_result()
if result:
parsed = DoneResult.model_validate_json(result)
return parsed.model_dump_json()
return ""
except Exception as e:
raise Exception(f"Browser task failed: {str(e)}")
finally:
await browser.close()
def invoke(self, input_data: Dict[str, Any]) -> BrowserUseOutput:
try:
task = input_data.get("task")
if not task:
return BrowserUseOutput(
result="", status="error", error="No task provided"
)
result = asyncio.run(self._process_browser_task(task))
return BrowserUseOutput(result=result, status="success")
except Exception as e:
return BrowserUseOutput(result="", status="error", error=str(e))
async def ainvoke(self, input_data: Dict[str, Any]) -> BrowserUseOutput:
try:
task = input_data.get("task")
if not task:
return BrowserUseOutput(
result="", status="error", error="No task provided"
)
result = await self._process_browser_task(task)
return BrowserUseOutput(result=result, status="success")
except Exception as e:
return BrowserUseOutput(result="", status="error", error=str(e))
"question": "Go to https://ai-news.dev/ and give me the top 3 news shown in the page." を実行してみます。
最終的に得られた回答は、、、
以下は、提供された情報に基づく記事のリストです。
1. **タイトル**: Kaggle画像コンペでやっていること③ #機械学習
**URL**: [https://qiita.com](https://qiita.com)
**説明**: Kaggle画像コンペでのLossやAugmentationの工夫を解説します。タスク特化のLossやAugmentationの選定が重要です。
2. **タイトル**: Kaggle Competitions Grandmasterになるまでの6年半を振り返る
**URL**: [https://kaeru-nantoka.hatenablog.com](https://kaeru-nantoka.hatenablog.com)
**説明**: Kaggleを始めて6年半でCompetitions Grandmasterになりました。初サブはTitanicで、初メダルは銅、初金メダルは2019年です。
3. **タイトル**: 【独自】政府、「AI推進法案」を来年の通常国会に提出へ 偽情報は“罰則なし”
**URL**: [https://newsdig.tbs.co.jp](https://newsdig.tbs.co.jp)
**説明**: 政府は来年の通常国会にAI推進法案を提出する方針です。偽情報に関する罰則は法案に盛り込まれない予定です。26日にAIの利活用について議論が行われる予定です。問題なく連携できました。
WEBの情報取得の部分は、 Serp など色々ありますが、カスタマイズを考えるとある程度自分で実装したいわけですが、
かといって、Selenium などを訪問先サイト毎に書き換えるのも大変なので、ある程度抽象的に動いてほしいところです。
こんかいの BrouseUse はまさにかゆいところに手が届くサービスだと感じました。
なお、フォームへの入力などもできますし、
自動で Google ReCaptcha を突破し�ようと試みます。
この辺は問題がありそうなので、ReCaptcha を発見したら処理を止めるPrompot を入れるとよいです。ちゃんと止まってくれます。